后缀数组常用的算法有两种,一种是倍增,一种是DC3,其中DC3是线性的,不过代码更恶心,常数也比较大,这里本人就先讲一下倍增的做法,虽然时间复杂度略差,不过还是很好用的。
作用介绍
我们有一个长度为$n$的字符串$s$,下标从$1$开始,我们用编号为$i$的后缀表示从$i$位置开始的后缀,这样就一共有$n$个后缀,后缀数组的作用就是将所有的后缀按字典序排序(从小到大),我们用$sa$数组、$rk$数组、$height$数组存储求得的信息
$sa[i]$代表排名第$i$位的后缀的编号
$rk[i]$代表编号为$i$的后缀的排名
$height[i]$代表排名为$i$的后缀和排名为$i-1$的后缀的最长公共前缀,很明显,$height[1]=0$
如果$s=aababb$,那么我们有6个后缀:$aababb、ababb、babb、abb、bb、b$,最后我们求得的各数组值如下(下标从小到大):
$sa:1,2,4,6,3,5$
$rk:1,2,5,3,6,4$
$height:0,1,2,0,1,1$
算法流程
我们先按照每个后缀的第一个字符对所有后缀排序,第一个字符相同的后缀之间的相对顺序不变,我们使用基数排序,一次基数排序的时间复杂度是$O(n)$,然后倍增地进行,时间复杂度$O(n log n)$。
当所有后缀按前$k$个字符排好序后,我们考虑按前$2k$个字符来排序,前$k$个字符为第一关键字,$k+1\sim 2k$个字符为第二关键字,先按第二关键字排序,再按第一关键字排序,其中使用离散化。
然后对于求$height[i]$,设$h[i]$表示$height[rk[i]]$,即编号为$i$的后缀与排名在它前一个的后缀的最长公共前缀,而$h[i]\ge h[i-1]-1$,我们可以$O(n)$的求出$height$数组,时间复杂度分析类似于$KMP$算法,采用的是势能分析法。
关于$h[i]\ge h[i-1]-1$的证明:


Talk is cheap,show me the code.
代码实现
$copy$的$y$总代码,加了注释。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1000010;
int n, m;
char s[N];
//sa是排名对应的编号,rk是编号对应的排名
int sa[N], x[N], y[N], c[N], rk[N], height[N];//x是按第一关键字的排名,y是按第二关键字的排名,x是编号对应排名,y是排名对应编号
void get_sa(){
//所有后缀首先按第一个字符进行基数排序
for (int i = 1; i <= n; i ++ ) c[x[i] = s[i]] ++ ;
for (int i = 2; i <= m; i ++ ) c[i] += c[i - 1];
//从后往前可以保证排序稳定
for (int i = n; i; i -- ) sa[c[x[i]] -- ] = i;
for (int k = 1; k <= n; k <<= 1){//倍增,当前已按前k个字母排好序
int num = 0;
//按第二关键字排序
for (int i = n - k + 1; i <= n; i ++ ) y[ ++ num] = i;//后k个字符没有第二关键字,因此排名最靠前
for (int i = 1; i <= n; i ++ )//其它的取决于它前面k个位置处的第一关键字的排名,按第一关键字的排名顺序枚举
if (sa[i] > k)
y[ ++ num] = sa[i] - k;
//按第一关键字排序
for (int i = 1; i <= m; i ++ ) c[i] = 0;
for (int i = 1; i <= n; i ++ ) c[x[i]] ++ ;
for (int i = 2; i <= m; i ++ ) c[i] += c[i - 1];
//从后往前,保证第一关键字相同时第二关键字排好的相对顺序不变
//y[i]是排名为i的对应的编号,看不懂的推荐看看基数排序的双关键字排序
for (int i = n; i; i -- ) sa[c[x[y[i]]] -- ] = y[i], y[i] = 0;
//y没用了
swap(x, y);
//排名为1的对应编号的排名为1
x[sa[1]] = 1, num = 1;
for (int i = 2; i <= n; i ++ )
//看看是否有相同的,第一关键字和第二关键字都要比较
x[sa[i]] = (y[sa[i]] == y[sa[i - 1]] && y[sa[i] + k] == y[sa[i - 1] + k]) ? num : ++ num;
if (num == n) break;//已经排完了
m = num;//修改下离散的范围
}
}
void get_height(){
for (int i = 1; i <= n; i ++ ) rk[sa[i]] = i;
for (int i = 1, k = 0; i <= n; i ++ ){
if (rk[i] == 1) continue;
if (k) k -- ;
int j = sa[rk[i] - 1];
while (i + k <= n && j + k <= n && s[i + k] == s[j + k]) k ++ ;
height[rk[i]] = k;
}
}
int main(){
scanf("%s", s + 1);//读入需要处理的字符串
n = strlen(s + 1), m = 122;//m是离散化的数据范围,因为一般处理的字符中ASCII码最大的也就是z,所以这里赋值为122
get_sa();
get_height();
return 0;
}求不同子串个数
给定一个字符串,有了$height$数组,我们就很容易求出不同子串个数(即字典序不同),我们已经按字典序给所有的后缀排好序,不同子串个数就相当于所有后缀的不同前缀个数。我们按字典序从前往后遍历所有后缀。
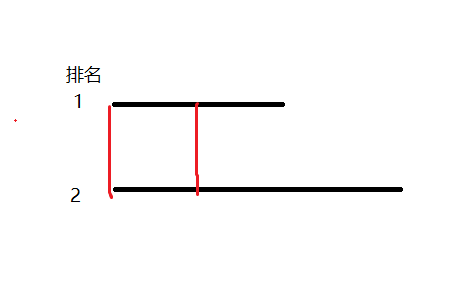
很明显,第一个后缀的所有前缀都应该被我们统计进答案,而第二个后缀的前缀恰有$height[i]$个是与前面的重复的,这样我们扫一遍$height$数组即可得到本质不同子串个数了。有同学可能会问,你这样统计到排名为i的后缀时,有没有可能与前面的后缀有一些公共前缀没减去?答案是:不会!
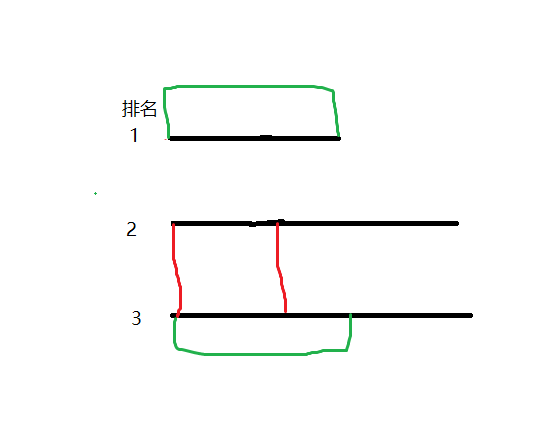
当出现如图所示情况时我们会有上述错误,然而这种清况不可能出现,因为我们在上面得到了$lcp(i,j)=min(lcp(i,k),lcp(k,j))(i\le k \le j)$
代码很简单。
LL ans=0;//记录答案
for(int i=1;i<=n;i++){//根据排名遍历
int id=sa[i];//找到对应编号
int len=n-id+1;//计算出长度
ans+=len-height[i];//统计答案
}求两个串的LCS
我们把两个串拼接起来,建一下后缀数组,然后根据$height$数组判断一下即可
scanf("%s",s+1);
int len=strlen(s+1);
scanf("%s",s+len+1);
n=strlen(s+1),m='z';
get_sa();
get_height();
int ans=0;
for(int i=2;i<=n;++i)//只用看排名相邻的就可以了,因为排名离得远的话不会变大
if(height[i]>ans&&((sa[i]<=len&&sa[i-1]>len)||(sa[i]>len&&sa[i-1]<=len)))//判断是否是两个字符串的
ans=height[i];后缀排序
板子题:后缀排序
品酒大会
$NOI2015$:品酒大会
两杯酒$l、r$是$k$相似的,等价于$lcp(i,j)\ge k$,当我们求两杯$k$相似的酒相调的方案数时,我们可以考虑该字符串所有后缀按字典序排序的序列,我们发现可以相调的酒被分成了若干段,因为我们有性质:$lcp(i,j)=min(lcp(i,k),lcp(k,j))(i\le k \le j)$。我们只需要知道这些段的大小$sz$,方案数就是$sz\times (sz-1)\div 2$,然后我们考虑倒着来求,因为这样的话刚开始所有酒都是单独一段,我们后面只需不断合并,这样比正着分裂好做得多(我还不知道正着能不能做),合并的同时维护每一段的最大值、次大值、最小值、次小值用来求可以得到的最大美味度。
#include<bits/stdc++.h>
#define x first
#define y second
#define endl '\n'
#define lowbit(x) ((x)&(-x))
#define all(x) (x).begin(),(x).end()
#define mp make_pair
#define pb push_back
#define SZ(x) ((int)(x).size())
#define rep(i,a,n) for (int i=a;i<n;i++)
#define per(i,a,n) for (int i=n-1;i>=a;i--)
using namespace std;
typedef pair<int,int> PII;
typedef vector<int> VI;
typedef long long LL;
typedef unsigned long long ULL;
typedef double DB;
mt19937 randint(random_device{}());
mt19937_64 randLL(random_device{}());
template<typename T=int>
T gcd(T a,T b){return b?gcd(b,a%b):a;}
template<typename T=int>
T qmi(T a,T b,T p){T res=1;while(b){if(b&1)res=(LL)res*a%p;b>>=1;a=(LL)a*a%p;}return res%p;}
template<typename T=int>
T read(){
T x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
//并查集板子
struct DSU{
vector<int> p,sz;
DSU(int n=0):p(n+1),sz(n+1){for(int i=1;i<=n;i++) p[i]=i,sz[i]=1;}
void init(int n){
p.resize(n+1);
sz.resize(n+1);
for(int i=1;i<=n;i++) p[i]=i,sz[i]=1;
}
int find(int x){
if(p[x]!=x) p[x]=find(p[x]);
return p[x];
}
void merge(int a,int b){
a=find(a),b=find(b);
if(a!=b) p[a]=b,sz[b]+=sz[a];
}
bool same(int a,int b){
a=find(a),b=find(b);
return a==b;
}
int cnt(){
int res=0;
for(int i=1;i<p.size();i++){
if(p[i]==i)
res++;
}
return res;
}
};
//----------------------------------------head------------------------------------
const int mod=1e9+7,N=3e5+10;
const LL INF=2e18;
const double eps=1e-6;
using PLL=pair<LL,LL>;
int n,m,w[N];
char s[N];
int sa[N],x[N],y[N],c[N],rk[N],height[N];
LL ma2[N],mi2[N],mi[N],ma[N];
vector<int> to[N];
PLL ans[N];
LL cnt,maxans=-INF;
DSU dsu;
//后缀数组板子
void get_sa(){
for(int i=1;i<=n;i++) c[x[i]=s[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i;i--) sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1){
int num=0;
for(int i=n-k+1;i<=n;i++) y[++num]=i;
for(int i=1;i<=n;i++)
if(sa[i]>k)
y[++num]=sa[i]-k;
for(int i=1;i<=m;i++) c[i]=0;
for(int i=1;i<=n;i++) c[x[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i;i--) sa[c[x[y[i]]]--]=y[i],y[i]=0;
swap(x,y);
x[sa[1]]=1,num=1;
for(int i=2;i<=n;i++)
x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&sa[i]+k<=n&&sa[i-1]+k<=n&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
if(num==n) break;
m=num;
}
}
void get_height(){
for(int i=1;i<=n;i++) rk[sa[i]]=i;
for(int i=1,k=0;i<=n;i++){
if(rk[i]==1) continue;
if(k) k--;
int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) k++;
height[rk[i]]=k;
}
}
LL get(int x){
return 1ll*(x-1)*x/2;
}
void calc(int x){
for(auto tar:to[x]){//每次是合并它和它的前一个,tar是排名
int a=dsu.find(tar-1),b=dsu.find(tar);
cnt-=get(dsu.sz[a])+get(dsu.sz[b]);//减去原来这两块的贡献
dsu.merge(a,b);//把a合并到b上
cnt+=get(dsu.sz[b]);//加上新的一块的贡献
//维护新一块的最大值、最小值、次大值、次小值
if(ma[a]>=ma[b]){
ma2[b]=max(ma2[a],ma[b]);
ma[b]=ma[a];
}
else ma2[b]=max(ma[a],ma2[b]);
if(mi[a]<=mi[b]){
mi2[b]=min(mi2[a],mi[b]);
mi[b]=mi[a];
}
else mi2[b]=min(mi2[b],mi[a]);
//更新答案
maxans=max(maxans,max(mi[b]*mi2[b],ma[b]*ma2[b]));
}
if(maxans==-INF) ans[x]={cnt,0};
else ans[x]={cnt,maxans};
}
void solve(){
n=read(),m='z';
dsu.init(n);
scanf("%s",s+1);
for(int i=1;i<=n;i++) w[i]=read();
get_sa();
get_height();
for(int i=2;i<=n;i++) to[height[i]].pb(i);//因为我们每次合并是和前一个合并,因此不需要0
for(int i=1;i<=n;i++){//按排名顺序记录每一段的信息
ma[i]=mi[i]=w[sa[i]];
ma2[i]=-INF,mi2[i]=INF;
}
for(int i=n-1;i>=0;i--) calc(i);//倒着合并,先把height[i]==n-1的合并,然后以此类推
for(int i=0;i<n;i++) printf("%lld %lld\n",ans[i].x,ans[i].y);
}
signed main(){
int t=1;
while(t--) solve();
return 0;
}生成魔咒
$SDOI2016$:生成魔咒
之前我们已经介绍了如何求一个字符串的不同子串个数,这次我们要求的好像是一个动态的问题,这让我们难以下手。然而,我们巧妙转换,我们倒着读入字符串,而一个字符串不管正着还是倒着其不同子串个数还是一样的,每次从前面删除一个字符,就可以完成题目的要求,删除的话我们使用一个双链表,$O(1)$删除。
#include<bits/stdc++.h>
#define x first
#define y second
#define endl '\n'
#define lowbit(x) ((x)&(-x))
#define all(x) (x).begin(),(x).end()
#define mp make_pair
#define pb push_back
#define SZ(x) ((int)(x).size())
#define rep(i,a,n) for (int i=a;i<n;i++)
#define per(i,a,n) for (int i=n-1;i>=a;i--)
using namespace std;
typedef pair<int,int> PII;
typedef vector<int> VI;
typedef long long LL;
typedef unsigned long long ULL;
typedef double DB;
mt19937 randint(random_device{}());
mt19937_64 randLL(random_device{}());
template<typename T=int>
T gcd(T a,T b){return b?gcd(b,a%b):a;}
template<typename T=int>
T qmi(T a,T b,T p){T res=1;while(b){if(b&1)res=(LL)res*a%p;b>>=1;a=(LL)a*a%p;}return res%p;}
template<typename T=int>
T read(){
T x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
//----------------------------------------head------------------------------------
const int INF=0x3f3f3f3f,mod=1e9+7,N=1e5+10;
const double eps=1e-6;
unordered_map<int,int> cast;
int n,m;
LL res,ans[N];
int u[N],d[N];
int s[N];
int sa[N],x[N],y[N],c[N],rk[N],height[N];//sa[i]是i排名对应的编号,rk[i]是编号对应排名,height[i]是排名为i的与i-1的lcp,x[i]是编号对应排名,y[i]是排名对应编号
void get_sa(){
for(int i=1;i<=n;i++) c[x[i]=s[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i;i--) sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1){
int num=0;
for(int i=n-k+1;i<=n;i++) y[++num]=i;
for(int i=1;i<=n;i++)
if(sa[i]>k)
y[++num]=sa[i]-k;
for(int i=1;i<=m;i++) c[i]=0;
for(int i=1;i<=n;i++) c[x[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i;i--) sa[c[x[y[i]]]--]=y[i],y[i]=0;
swap(x,y);
x[sa[1]]=1,num=1;
for(int i=2;i<=n;i++)
x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&sa[i]+k<=n&&sa[i-1]+k<=n&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
if(num==n) break;
m=num;
}
}
void get_height(){
for(int i=1;i<=n;i++) rk[sa[i]]=i;
for(int i=1,k=0;i<=n;i++){
if(rk[i]==1) continue;
if(k) k--;
int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) k++;
height[rk[i]]=k;
}
}
int get(int x){
if(cast.count(x)) return cast[x];
return cast[x]=++m;
}
void solve(){
n=read();
for(int i=n;i;i--) s[i]=read(),s[i]=get(s[i]);
for(int i=1;i<=n;i++) u[i]=i-1,d[i]=i+1;//这里维护的是排名的双链表,从上往下维护,u[i]表示i上面的那个串的排名,d[i]表示i下面的那个串的排名
get_sa();
get_height();
u[n+1]=n,d[0]=1;
for(int i=1;i<=n;i++)
res+=n-sa[i]+1-height[i];
for(int i=1;i<=n;i++){//删除编号为i的
int k=rk[i],j=d[k];//找到该编号对应的排名以及它的后一名
ans[i]=res;
//先减去它有贡献的地方
res-=n-sa[k]+1-height[k];
res-=n-sa[j]+1-height[j];
height[j]=min(height[j],height[k]);//lcp(i,j)=min(lcp(i,k),lcp(k,j))(i<=k<=j)
d[u[k]]=j,u[j]=u[k];//删除这一名
res+=n-sa[j]+1-height[j];//加上新的
}
for(int i=n;i;i--) cout<<ans[i]<<endl;//倒着输出
}
signed main(){
int t=1;
while(t--) solve();
return 0;
}最近要补的知识点比较多,线段树的先鸽着。

